使用指标和链路诊断内存泄漏
OpenTelemetry 提供的应用遥测数据对于诊断分布式系统中的问题非常有用。 在这个场景中,我们将逐步演示如何从宏观指标与追踪数据入手,定位内存泄漏问题的根源。
设置
要运行此场景,你需要部署演示应用程序并启用 recommendationServiceCacheFailure 功能标志。
启用功能标志后,让应用程序运行约 10 分钟左右,以便填充数据。
诊断
诊断问题的第一步是确定问题存在。 通常,第一步是查看由 Grafana 等工具提供的指标仪表板。
启动演示后,应该会有一个演示仪表板文件夹,其中包含两个仪表板。 一个用于监控 OpenTelemetry Collector,另一个包含多个查询和图表,用于分析每个服务的延迟和请求率。
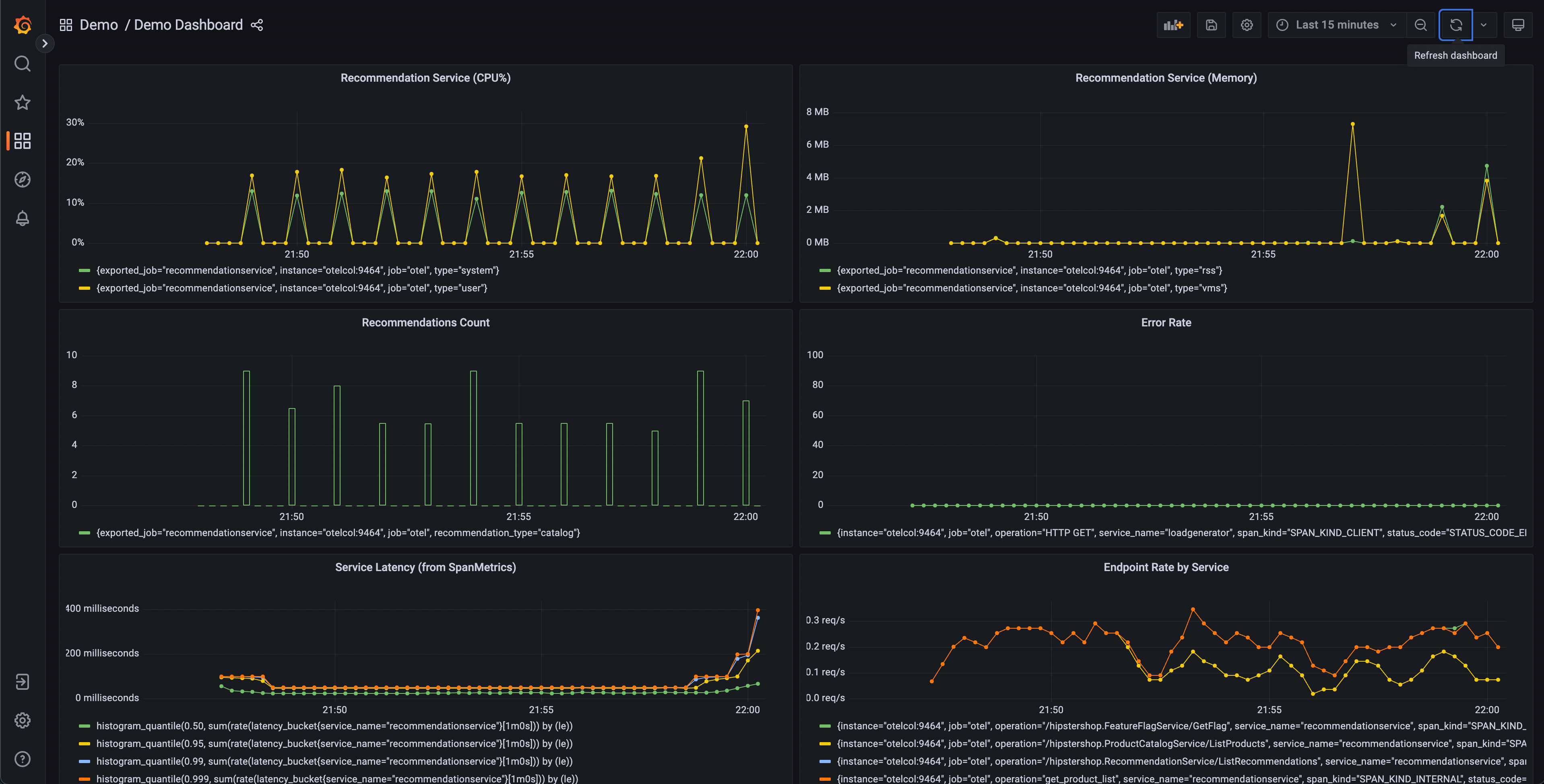
该仪表板将包含多个图表,但有几个应该会引起注意:
- 推荐服务(CPU% 和内存)
- 服务延迟(来自 SpanMetrics)
- 错误率
推荐服务图表由导出到 Prometheus 的 OpenTelemetry 指标生成。 而服务延迟和错误率图表由 OpenTelemetry 采集器 Span Metrics 处理器生成。
从我们的仪表盘可以看出,推荐服务似乎出现了异常行为——CPU 使用率呈尖峰式波动, 且 p95、p99 及 p99.9 延迟直方图均呈现出长尾延迟现象。 我们还可以看到该服务的内存利用率存在间歇性峰值。
我们知道我们的应用程序也在发送链路数据,所以让我们考虑另一种确定问题存在的方法。
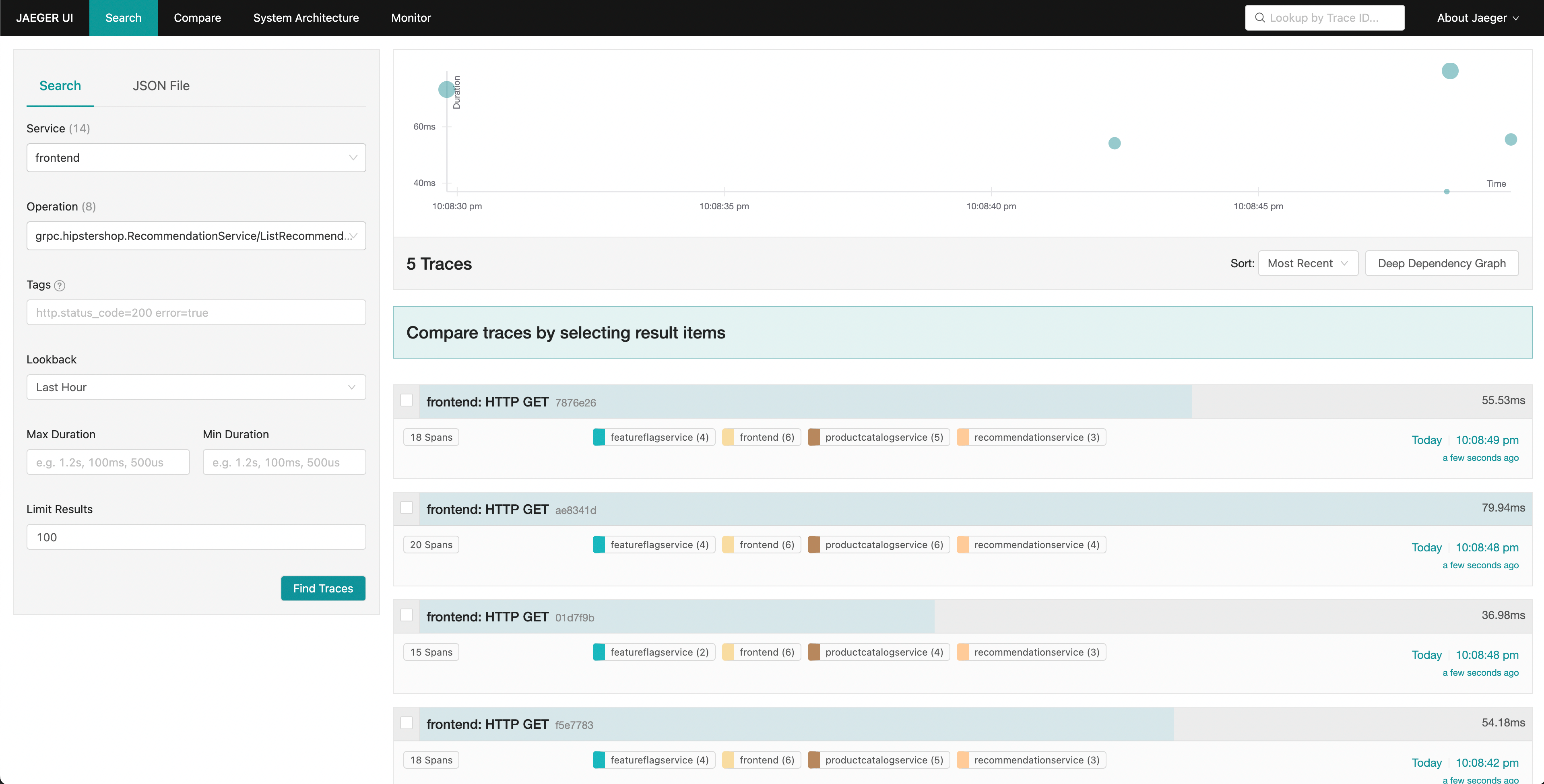
Jaeger 允许我们搜索链路并显示整个请求的端到端延迟,并可以查看整体请求的每个部分。 也许我们注意到前端请求的尾部延迟增加。 Jaeger 允许我们搜索和过滤链路,只包含那些包含对推荐服务请求的链路。
通过按延迟排序,我们可以快速找到耗时较长的特定链路。 点击右侧面板中的链路,我们可以查看瀑布图。
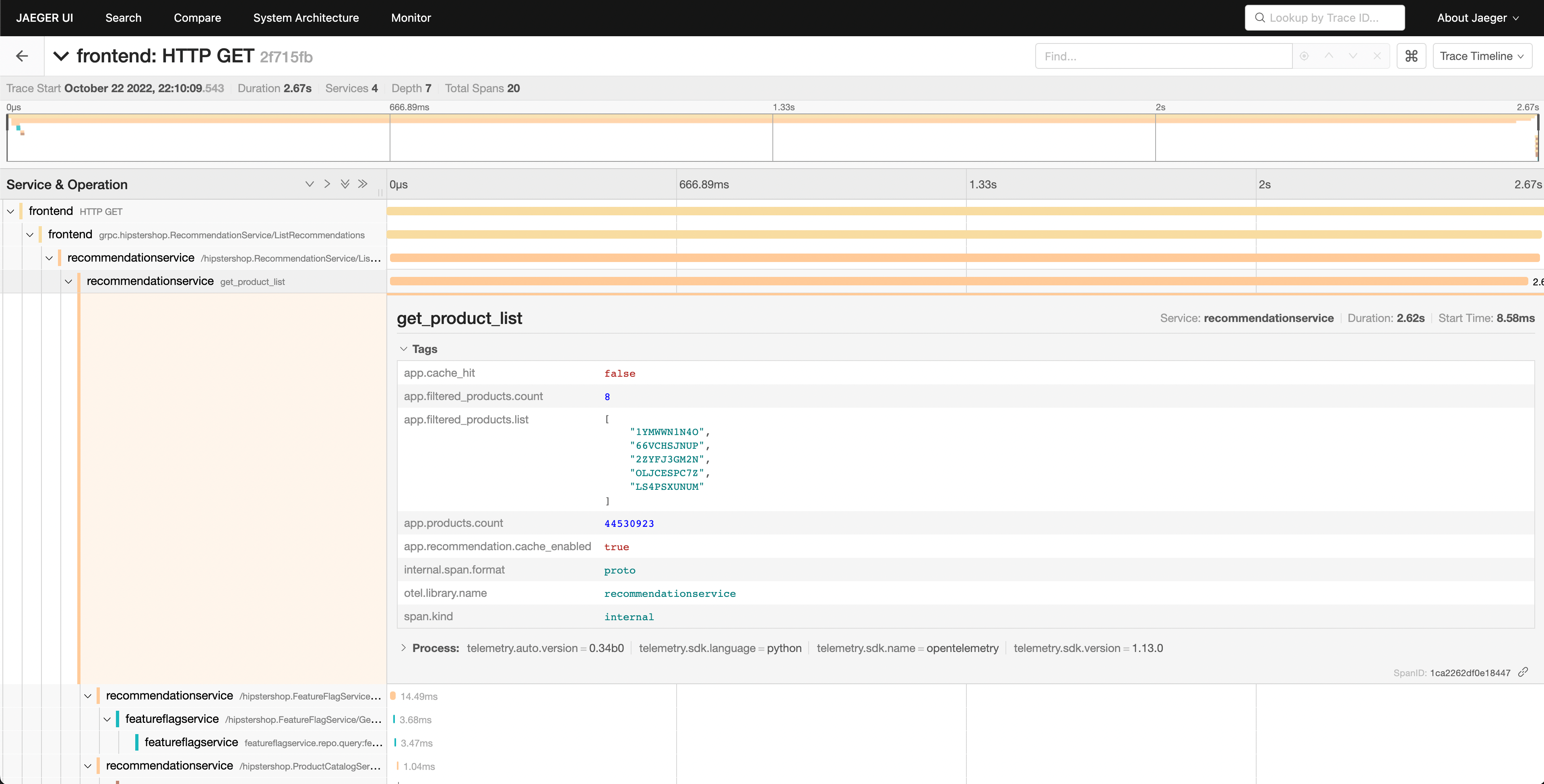
我们可以看到推荐服务需要很长时间才能完成工作,查看详细信息可以让我们更好地了解发生了什么。
确认诊断
在瀑布图中,我们可以看到 app.cache_hit 属性设置为 false,而 app.products.count 值非常高。
返回搜索 UI,在 Service 下拉菜单中选择 recommendation。
在 Tags 框中搜索 app.cache_hit=true。
请注意,当缓存命中时,请求往往会更快。
现在搜索 app.cache_hit=false 并比较延迟。
你应该会注意到链路列表顶部的可视化有所变化。
由于本场景是刻意构造的演示,因此我们清楚该在代码的哪个位置找到引发问题的底层漏洞。 然而,在现实场景中,我们可能需要进一步搜索来了解代码中发生了什么,或者导致问题的服务之间的交互。
意见反馈
这个页面对您有帮助吗?
Thank you. Your feedback is appreciated!
Please let us know how we can improve this page. Your feedback is appreciated!