OpenTelemetry Java メトリクスのパフォーマンス比較
Blog posts are not updated after publication. This post is more than a year old, so its content may be outdated, and some links may be invalid. Cross-verify any information before relying on it.
OpenTelemetry の最大の価値提案は、言語に依存しない汎用的なオブザーバビリティ標準を目指していることでしょう。 トレース、メトリクス、ログ(そしてまもなくプロファイリングも!)のツールを提供し、多くの一般的な言語で実装を提供することで、OpenTelemetry はポリグロットチームの認知負荷を軽減し、1つの語彙と1つのツールキットを提供します。
これらはすべて事実ですが、今日は特定のシグナルと言語にズームインして、OpenTelemetry Java メトリクス SDK のパフォーマンスについて話したいと思います。
メトリクス入門
メトリクスは多義的な用語ですが、オブザーバビリティの分野では、多くの個別の計測を集約するためにメトリクスを使います。 すべての個別の計測をエクスポートする場合と比較して、集約結果をエクスポートすることで、データ量の観点からはるかにコンパクトなフットプリントになります。 ただし、集約プロセスで情報が根本的に失われるため、いくつかの分析形態を諦めることになります。
パフォーマンスの観点から、計測を記録するために必要な CPU / メモリは、メトリクスシステムの重要な特性です。 数百万や数十億の計測を記録する可能性があるからです。 さらに、集約されたメトリクスをプロセス外にエクスポートするための CPU / メモリも重要です。 エクスポートは定期的に行われ、アプリケーションの「ホットパス」上にはありませんが、リソースを消費するため、パフォーマンスに断続的な影響を与える可能性があります。
例
ここでは、以降の説明で参照できる例を紹介しましょう。
OpenTelemetry で最も有用なメトリクスの1つは http.server.request.duration で、HTTP サーバーが処理した各リクエストのレスポンスレイテンシーの計測を記録し、ヒストグラムに集約します。
各計測にはさまざまな属性(またはラベル、タグ、ディメンション)が関連付けられていますが、簡単のために http.request.method、http.route、http.response.status_code に焦点を当てましょう。
詳細については HTTP セマンティック規約を参照してください。
これにより、スループット、平均レスポンスタイム、最小・最大レスポンスタイム、パーセンタイルレスポンスタイム(p95、p99 など)を、HTTP メソッド、ルート、レスポンスステータスコードなどで分類して計算できます。
このメトリクスに計測を記録するには、HTTP サーバーが受信する各リクエストに対して以下を行います。
- リクエストのライフサイクルのできるだけ早い段階で開始時刻を記録します(遅延するとメトリクスの精度が低下します)。
- リクエストを処理してレスポンスを返します。
- レスポンスが返された直後に、現在時刻と最初に記録した開始時刻の差分を記録します。 この所要時間がリクエストレイテンシーです。
- リクエストコンテキストから
http.request.method、http.route、http.response.status_code属性キーの値を抽出します。 http.server.request.durationヒストグラム計装に、計算されたリクエストレイテンシーと属性からなる計測を記録します。
メトリクスシステムは、これらの計測を、出現した属性キー・値のペア(http.request.method、http.route、http.response.status_code)の一意の組み合わせごとに個別のシリーズに集約します。
定期的に、メトリクスは収集されプロセス外にエクスポートされます。
このエクスポートプロセスは、アプリケーションが一定間隔でメトリクスをどこかにプッシュする「プッシュベース」か、別のプロセスが一定間隔でアプリケーションからメトリクスをプル(またはスクレイプ)する「プルベース」のいずれかです。
OpenTelemetry では、OTLP が「プッシュベース」のプロトコルであるため、プッシュが推奨されます。
次のオペレーションを持つシンプルな HTTP サーバーがあると仮定します。
GET /usersGET /users/{id}PUT /users/{id}
これらは通常 200 OK HTTP ステータスコードを返しますが、404 が返される可能性もあります(その他のエラーも同様)。
http.server.request.duration ヒストグラムに計測を記録する Java の擬似コードは次のようになります。
// 計装の初期化
DoubleHistogram histogram = meterProvider.get("my-instrumentation-name")
.histogramBuilder("http.server.request.duration")
.setUnit("s")
.setExplicitBucketBoundariesAdvice(Arrays.asList(1.0, 5.0, 10.0)) // ヒストグラムのバケット境界を関心のあるしきい値に設定
.build();
// ... コードの別の場所で、処理した各 HTTP リクエストの計測を記録
histogram.record(22.0, httpAttributes("GET", "/users", 200));
histogram.record(7.0, httpAttributes("GET", "/users/{id}", 200));
histogram.record(11.0, httpAttributes("GET", "/users/{id}", 200));
histogram.record(4.0, httpAttributes("GET", "/users/{id}", 200));
histogram.record(6.0, httpAttributes("GET", "/users/{id}", 404));
histogram.record(6.2, httpAttributes("PUT", "/users/{id}", 200));
histogram.record(7.2, httpAttributes("PUT", "/users/{id}", 200));
// ヘルパー定数
private static final AttributeKey<String> HTTP_REQUEST_METHOD = AttributeKey.stringKey("http.request.method");
private static final AttributeKey<String> HTTP_ROUTE = AttributeKey.stringKey("http.route");
private static final AttributeKey<String> HTTP_RESPONSE_STATUS_CODE = AttributeKey.stringKey("http.response.status_code");
// ヘルパー関数
private static Attributes httpAttributes(String method, String route, int responseStatusCode) {
return Attributes.of(
HTTP_REQUEST_METHOD, method,
HTTP_ROUTE, route,
HTTP_RESPONSE_STATUS_CODE, responseStatusCode);
}
エクスポートの時間になると、集約されたメトリクスはシリアライズされ、プロセス外に送信されます。 この例では、出力メトリクスのシンプルなテキストエンコーディングを含めました。 実際のアプリケーションでは、Prometheus テキストフォーマットや OTLP など、使用するプロトコルで定義されたエンコーディングを使用します。
2024-05-20T18:05:57Z: http.server.request.duration:
attributes: {"http.request.method":"GET","http.route":"/users/{id}","http.response.status_code":200}
value: {"count":3,"sum":22.0,"min":4.0,"max":11.0,"buckets":[[1.0,0],[5.0,1],[10.0,1]]}
attributes: {"http.request.method":"GET","http.route":"/users/{id}","http.response.status_code":404}
value: {"count":1,"sum":6.0,"min":6.0,"max":6.0,"buckets":[[1.0,0],[5.0,0],[10.0,1]]}
attributes: {"http.request.method":"GET","http.route":"/users","http.response.status_code":200}
value: {"count":1,"sum":22.0,"min":22.0,"max":22.0,"buckets":[[1.0,0],[5.0,0],[10.0,0]]}
attributes: {"http.request.method":"PUT","http.route":"/users/{id}","http.response.status_code":200}
value: {"count":2,"sum":13.4,"min":6.2,"max":7.2,"buckets":[[1.0,0],[5.0,0],[10.0,2]]}
http.server.request.duration メトリクスには、http.request.method、http.route、http.response.status_code の値の一意な組み合わせが4つあるため、4つの異なるシリーズがあることに注目してください。
これらの各シリーズには、カウント(つまり合計カウント)、合計、最小値、最大値、およびバケット境界とバケットカウントのペアの配列で構成されるヒストグラムがあります。
この例は些細なものですが、これを数百万や数十億の計測を記録するレベルにスケールアウトすることを想像してください。 集約されたメトリクスのメモリとシリアライゼーションのフットプリントは、一意なシリーズの数に比例し、記録された計測の数に関係なく一定に保たれます。 データのフットプリントと計測数のこの分離が、メトリクスシステムの根本的な価値です。
良いメトリクスシステムとは何か
メトリクスシステムは計測を記録し、集約された状態を収集またはプロセス外にエクスポートします。 これら2つの操作を個別に検討しましょう。
記録側では、メトリクスシステムは以下を行う必要があります。
- 計測の属性に基づいて、更新すべき適切な集約状態を見つけます。 一部のシステムでは、API 呼び出し元が集約状態への直接参照を保持するハンドルをリクエストでき、検索が不要です。 これらの参照は、特定の属性セットにバインドされているため、バウンド計装と呼ばれることがあります。 多くの場合、属性値をアプリケーションコンテキストを使用して計算する必要があるため、これは不可能です(たとえば、この例では HTTP リクエスト属性の値は、リクエストの処理結果に基づいて解決されます)。 メトリクスシステムがバウンド計装をサポートしていない場合、またはアプリケーションコンテキストで属性を計算する必要がある場合、メトリクスシステムは通常、計測の属性に対応するシリーズをマップで検索する必要があります。
- 集約状態をアトミックに更新します。 別のスレッドで収集が発生した場合でも、部分的に更新された状態が読み取られることがないようにする必要があります。
- 記録は高速かつスレッドセーフでなければなりません。 計測はアプリケーションのホットパス上で記録されるという期待があり、したがって記録にかかる時間はアプリケーションの SLA に直接影響します。 複数のスレッドが同じ属性で同時に計測を記録する可能性があるため、速度が正確性を犠牲にしないように注意し、競合を軽減する必要があります。
- 記録はメモリを割り当てるべきではありません。 記録は数百万回または数十億回行われます。 各記録がメモリを割り当てると、アプリケーションのパフォーマンスに影響を与える GC チャーンにさらされることになります。 メトリクスシステムが定常状態に達した後(つまり、すべてのシリーズが計測を受信した後)、計測の記録はメモリを一切割り当てるべきではありません。 これの例外は、記録される属性が事前にわからず、記録時にアプリケーションコンテキストから計算する必要がある場合です。 ただし、これらの割り当ては最小限であるべきで、メトリクスシステムではなくユーザーに帰属するものと言えるでしょう。
収集またはエクスポート側では、メトリクスシステムは以下を行う必要があります。
- すべての一意なシリーズ(つまり、計測を受信した一意な属性)を反復処理し、集約状態を読み取ります。
- 何らかのプロトコルを使用して集約状態をエンコードし、プロセス外にエクスポートします。 これは、別のプロセスが定期的にプルして読み取る Prometheus テキストフォーマットかもしれませんし、定期的にプッシュされる OTLP のようなものかもしれません。
- エクスポーターが常に増加する累積状態を要求するか、各収集後にリセットするデルタ状態を要求するかに応じて、各シリーズの状態をリセットする必要がある場合があります。
- 収集は記録操作への影響を最小限にする必要があります。 メトリクスの収集は、収集とは異なるスレッドで記録によってアトミックに更新される集約メトリクスの状態を読み取ることを意味します。 一般的に、パフォーマンスの優先度の面では、収集は記録に道を譲ります。 収集は、ホットパス上の記録操作をブロックする時間を最小限に抑えるよう努めるべきです。
- 収集はメモリの割り当てを最小限にすべきです。 収集時にいくらかの割り当ては避けられません(あるいは避けられないかもしれません……詳しくは読み進めてください)が、本当に最小限にすべきです。 そうしないと、高カーディナリティのメトリクス(つまり、多数の一意な属性セットで計測を記録するシステム)を記録するシステムは、収集時のメモリチャーンによる高いメモリ割り当てとその後の GC が発生します。 これにより、アプリケーションの SLA に影響を与える定期的なパフォーマンスの低下が引き起こされる可能性があります。
この例では、サーバーが応答する各 HTTP リクエストの所要時間を、そのリクエストを説明する属性セットとともに記録します。 属性に対応するシリーズを検索し(存在しない場合は新しいシリーズを作成し)、メモリに保持している状態(合計、最小値、最大値、バケットカウント)をアトミックに更新します。 収集時には、4つの一意なシリーズそれぞれの状態を読み取り、この些細な例では、情報の文字列エンコーディングを出力します。
OpenTelemetry Java メトリクス
OpenTelemetry Java プロジェクトは、高速で記録側でのメモリ割り当てがゼロ(または特定のケースでは低い)、収集側での割り当ても非常に少ない、高パフォーマンスのメトリクスシステムです。
この例を見て、舞台裏で何が起こっているかを分解してみましょう。
// 計測の記録
histogram.record(7.2, httpAttributes("PUT", "/users/{id}", 200));
// ヘルパー定数
private static final AttributeKey<String> HTTP_REQUEST_METHOD = AttributeKey.stringKey("http.request.method");
private static final AttributeKey<String> HTTP_ROUTE = AttributeKey.stringKey("http.route");
private static final AttributeKey<String> HTTP_RESPONSE_STATUS_CODE = AttributeKey.stringKey("http.response.status_code");
// ヘルパー関数
private static Attributes httpAttributes(String method, String route, int responseStatusCode) {
return Attributes.of(
HTTP_REQUEST_METHOD, method,
HTTP_ROUTE, route,
HTTP_RESPONSE_STATUS_CODE, responseStatusCode);
ヒストグラム計装に計測を記録するたびに、計測値と属性を引数として渡します。
この例では、アプリケーションコンテキストを使用してリクエストごとに属性を計算していますが、すべての一意な属性セットが事前にわかっている場合は、事前に割り当てて定数の Attributes 変数に保持することができ、また保持すべきです。
これにより不要なメモリ割り当てが削減されます。
ただし、属性が事前にわからない場合でも、属性キーは事前にわかります。
ここでは、属性に現れる各 AttributeKey の定数を事前に割り当てています。
OpenTelemetry Java の Attributes 実装は非常に効率的に実装されており、数年にわたってベンチマークと最適化が行われてきました。
内部的には、記録時にシリーズに対応する集約状態(OpenTelemetry Java の用語では AggregatorHandle)を検索する必要があります。
重い処理の大部分は ConcurrentHashMap<Attributes, AggregatorHandle> での検索によって実行されますが、いくつか注目すべき詳細があります。
AggregatorHandleを取得するプロセスは、記録と同時に別のスレッドで収集が行われている場合でも、競合を減らすように最適化されています。 取得されるロックは ConcurrentHashMap 内のものだけで、ConcurrentHashMap は複数のロックを使用して競合を減らしています。 各検索での CPU サイクルを節約するために、Attributesのハッシュコードをキャッシュしています。- エクスポーターが
AggregationTemporality=deltaの場合、各AggregatorHandleの状態は各収集後にリセットする必要があります。 各エクスポートサイクルで新しいAggregatorHandleインスタンスを再割り当てすることを避けるために、オブジェクトプーリングが使用されています。 - サポートされている各集約に対して異なる
AggregatorHandle実装があります。 実装はすべて、可能な限りコンペアアンドスワップ、LongAdder、Atomic*などの低競合ツールを使用し、収集間で状態を保持するために使用されるデータ構造を再利用するように最適化されています。 指数ヒストグラムの実装は、Math.logの使用を避けるために低レベルのビットシフトを使用してバケットを計算しています。 1ナノ秒が重要なのです!
収集時には、すべての計装を反復処理し、エクスポートに使用されるプロトコルに従って各 AggregatorHandle の状態を読み取りシリアライズする必要があります。
過去1年ほどで、収集サイクルのメモリ割り当てを最適化するために大規模な作業を行いました。
この最適化は、メトリクスのエクスポーターが同時に呼び出されることはないという認識から生まれています。
定期的にメトリクスの状態を読み取り、エクスポーターにシリアライズのために送信し、そのエクスポートが完了するまで待ってから再びメトリクスの状態を読み取ることを保証すれば、メトリクスの状態をエクスポーターに渡すために使用されるすべてのデータ構造を安全に再利用できます。
もちろん、一部のメトリクスリーダー(Prometheus メトリクスリーダーなど)はメトリクスの状態を同時に読み取る場合があります。
これらの場合は、最適化されたメモリ割り当てよりも安全性と正確性を優先します。
その結果、OpenTelemetry Java 固有の設定可能なオプションである MemoryMode が生まれました。
MetricReaders(または関連する MetricExporter)は、メトリクスの状態を同時に読み取るかどうかに基づいて、メモリモードを指定します。
現在、最適化されたメモリ動作(MemoryMode.reusable_data と呼ばれます)は環境変数を介してオプトインします。
将来的には、例外的なケースのみがメトリクスの状態への同時アクセスを必要とするため、最適化されたメモリモードがデフォルトで有効になります。
メトリクスの状態を保持するオブジェクト(OpenTelemetry Java の用語では MetricData)が、収集サイクルにおけるメモリ割り当てのほぼすべてを占めていることがわかりました。
これらを再利用することで(状態を保持するために使用されるその他の内部オブジェクトとともに)、コアメトリクス SDK のメモリ割り当てを99%以上削減しました。
詳しくはこちらのブログ記事をご覧ください。
次に、OTLP シリアライゼーションのパフォーマンスに注目しました。 OTLP は protobuf バイナリシリアライゼーションを使用してペイロードをエンコードします。 デフォルトの実装では、まずデータを protobuf メッセージを表す生成されたクラスに変換する必要があります。 これらのクラスと関連するシリアライゼーションロジックは大きな依存関係(com.google.protobuf:protobuf-java は 1.7MB)を必要とし、中間表現からの不要なメモリ割り当てが発生します。 数年前、私たちはこれらの問題を回避するために独自の OTLP シリアライゼーションを手書きしましたが、まだ改善の余地がありました。 OTLP ペイロードの生成には、シリアライズする前にリクエストボディのサイズを知る必要があるのです。 そのため、シリアライゼーション実装はデータを2回反復処理する必要があります。 1回目はペイロードサイズの計算、2回目はシリアライゼーションです。 途中で、UTF-8 エンコーディングの計算やその他の中間データの保存などの処理が必要になり、メモリ割り当てが発生します。 私たちは OTLP シリアライゼーションを作り直し、可能な限りステートレスな方法でペイロードサイズの計算とシリアライゼーションを行い、不可能な場合はデータ構造を再利用するようにしました。 opentelemetry-java:1.38.0 で初めてリリースされたこの動作は、前述の同じ MemoryMode オプションを使用して設定可能で、将来的にはデフォルトになる予定です。 (注: シリアライゼーションの最適化は、メトリクスに加えて OTLP トレースとログのシリアライゼーションにも適用されます!)
ベンチマーク: OpenTelemetry Java vs. Micrometer vs. Prometheus Java
OpenTelemetry Java で多くのパフォーマンスエンジニアリングを行ってきましたが、Java エコシステムの他の一般的なメトリクスシステムと比較してどうでしょうか。 最も人気のある(GitHub スター数を参照)2つの Java メトリクスシステム、micrometer と prometheus と比較しましょう。 dropwizard metrics も非常に人気がありますが、ディメンションがないため他のシステムと比較しにくいので除外しました。
方法論、結果、結論を共有する前に、システム間のベンチマーク比較における課題についていくつか注意事項があります。
- 標準的な語彙がありません。 OpenTelemetry の属性は micrometer ではタグ、prometheus ではラベルと呼ばれます。 micrometer と prometheus にはレジストリの概念がありますが、OpenTelemetry にはメトリクスリーダーとメトリクスエクスポーターがあります。 私は OpenTelemetry プロジェクトのメンバーであるため、用語が衝突する場合は OpenTelemetry の用語を使用します。
- 厳密に同条件の比較ができない場合があります。 OpenTelemetry の指数ヒストグラムに相当する micrometer の機能はありません。 OpenTelemetry はバウンド計装をサポートしていませんが、micrometer と prometheus はこれに大きく依存しています。 prometheus と micrometer は OTLP をサポートしていますが、OpenTelemetry は OTLP のために構築されており、いくつかの利点があります。
- 何を比較するかの判断。 これらのシステムでは多くの異なることができます。 どの側面が最も重要かについて、私自身の主観的な理由でベンチマーク対象をかなり選択的にしました。 それでも、精査すべき生データは大量にあります。 結果には、データを理解しやすくするための集約された視覚的補助が含まれています。
- すべてのシステムの専門家ではありません。 OpenTelemetry Java のメンテナーとして、その設定方法と使い方については熟知しています。 micrometer と prometheus はドキュメントに記載されているとおりに使用していますが、パワーユーザーなら知っているような設定や使い方の最適化を見落としている可能性があります。 知らないことが何かもわかりません。
方法論
方法論の説明とデータの解釈方法は以下のとおりです。
- これらのベンチマークを支えるコードは github.com/jack-berg/metric-system-benchmarks で利用可能で、生の結果データは Google スプレッドシートとして利用可能です。
- ベンチマークはローカルマシンで実行されました。 MacBook Pro w/ M1 Max、64GB RAM、Sonoma 14.3.1 です。
- システムの主要な側面を比較するために3つの異なるベンチマークがあります。
- 記録: 計測の記録にかかる CPU 時間とメモリ割り当てを比較します。
- 収集: メモリ内のメトリクス状態を読み取る(つまりエクスポートなし)ためのメモリ割り当てを比較します。
- 収集とエクスポート: メトリクス状態を読み取り OTLP レシーバーにプッシュするためのメモリ割り当てを比較します。
- 各ベンチマークについて、さまざまなシナリオが評価されます。
- 異なる計装の比較: カウンター、明示的バケットヒストグラム(OpenTelemetry デフォルトのバケット境界)、指数バケットヒストグラム。 micrometer は指数バケットヒストグラムをサポートしていません。
- 100 個の一意な属性セットに対応するシリーズに記録と収集を行います。 各属性セットには、ランダムな26文字の値を持つ単一のキー・値のペアがあります。 これは、属性の内容よりもカーディナリティの方が重要であるという私の直感を反映しています。
- 属性値が事前にわかっている場合(結果では「Attributes Known」)とわかっていない場合(チャートでは「Attributes Unknown」)のシナリオを比較し、アプリケーションがアプリケーションコンテキストを使用して属性を計算する必要があるかどうかを反映します。 属性が事前にわかっている場合、サポートされていればバウンド計装を取得します。 OpenTelemetry はバウンド計装をサポートしていませんが、micrometer と prometheus はサポートしています。 属性が事前にわかっていない場合、記録時に属性を計算します。
- 記録ベンチマークをシングルスレッドとマルチスレッドの両方のシナリオで実行します。 簡潔にするため、以下ではシングルスレッドの結果のみを示します。 マルチスレッドテストでは、ボトルネックがメトリクスシステムの実装上の決定から離れるため、システム間の差異が縮まる傾向があったためです。
- OpenTelemetry のシナリオでは、近い将来デフォルトにする予定のため
MemoryMode=reusable_dataを有効にします。 デフォルトではスパンが記録されているときのみエグゼンプラーを記録し、メトリクスシステムの比較を分離しているため、エグゼンプラーは無効にします。 - ベンチマークの実行には JMH を使用します。 誤った CPU やメモリ割り当てから分離するようにベンチマークを設定します。 たとえば、収集ベンチマークでは、純粋に収集プロセスを評価するために、すべての計測を事前に記録します。
- 結果は各計装タイプごとにグラフを分けています。 記録操作は1つのグラフシリーズで示されます。 収集および収集とエクスポートの結果は別のグラフシリーズで示されます。
結果
以下のグラフは記録ベンチマークの結果をまとめたものです。
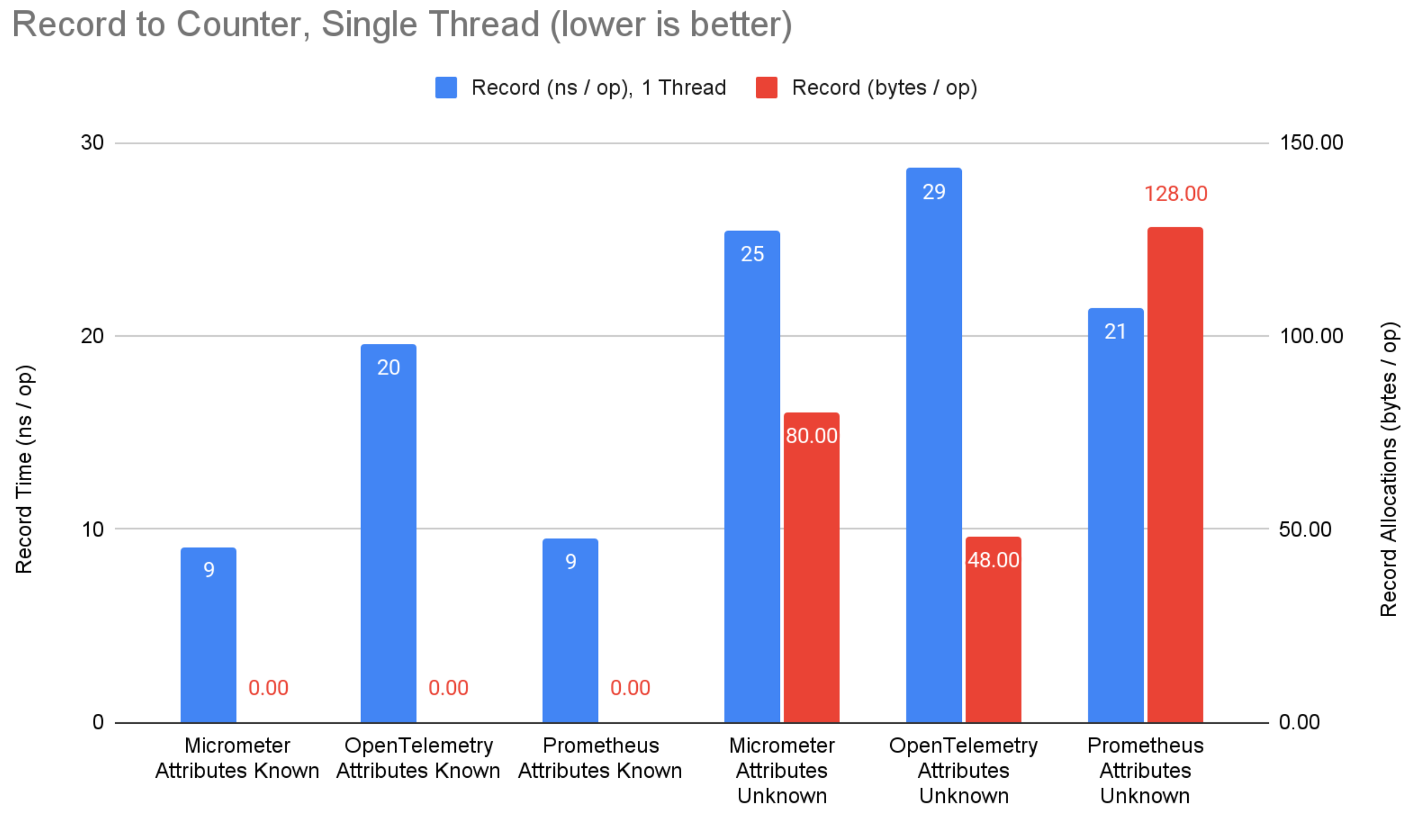
図1: カウンターへの記録ベンチマーク結果。
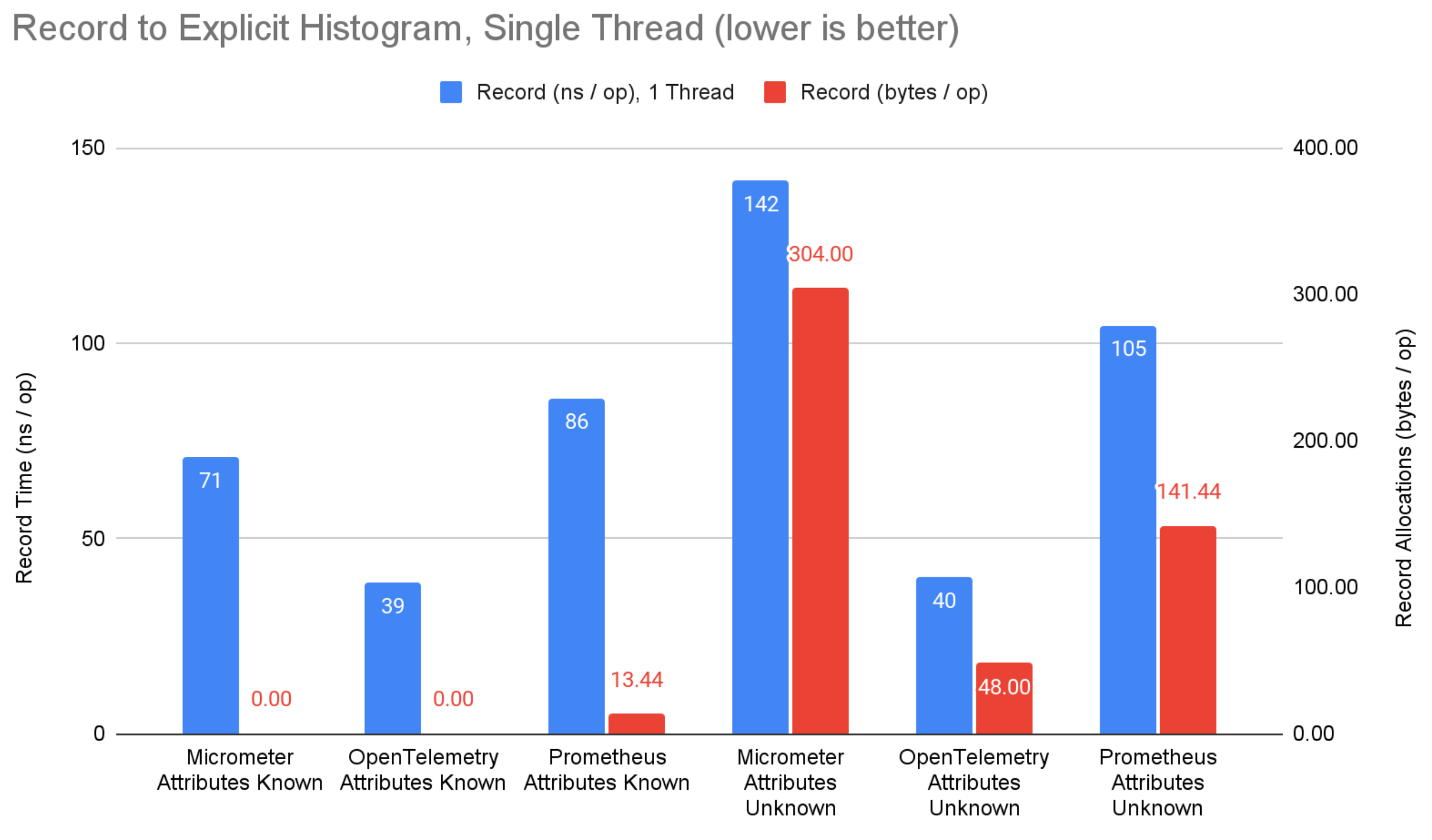
図2: 明示的バケットヒストグラムへの記録ベンチマーク結果。
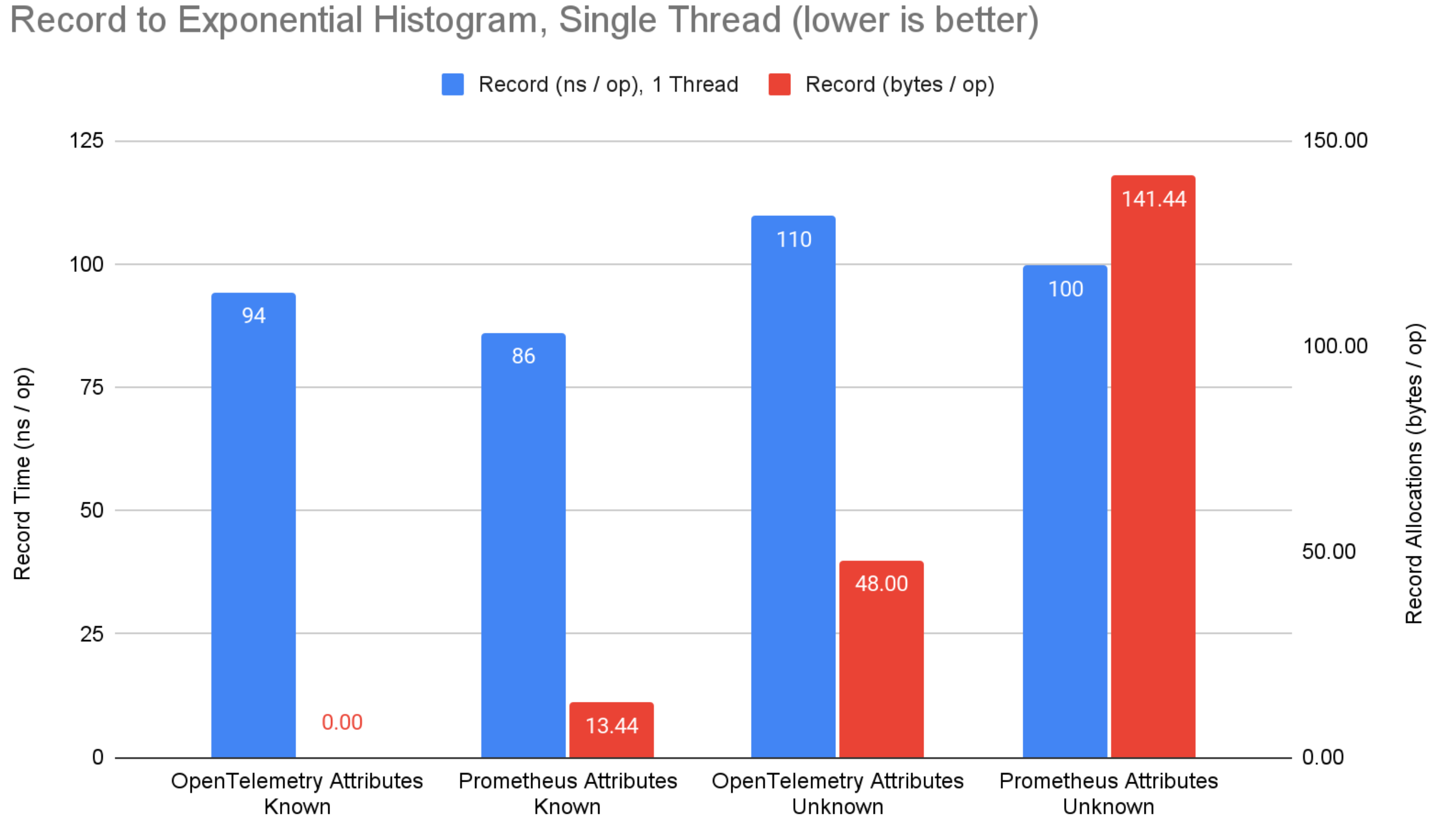
図3: 指数バケットヒストグラムへの記録ベンチマーク結果。
以下のグラフは収集および収集とエクスポートのベンチマーク結果をまとめたものです。
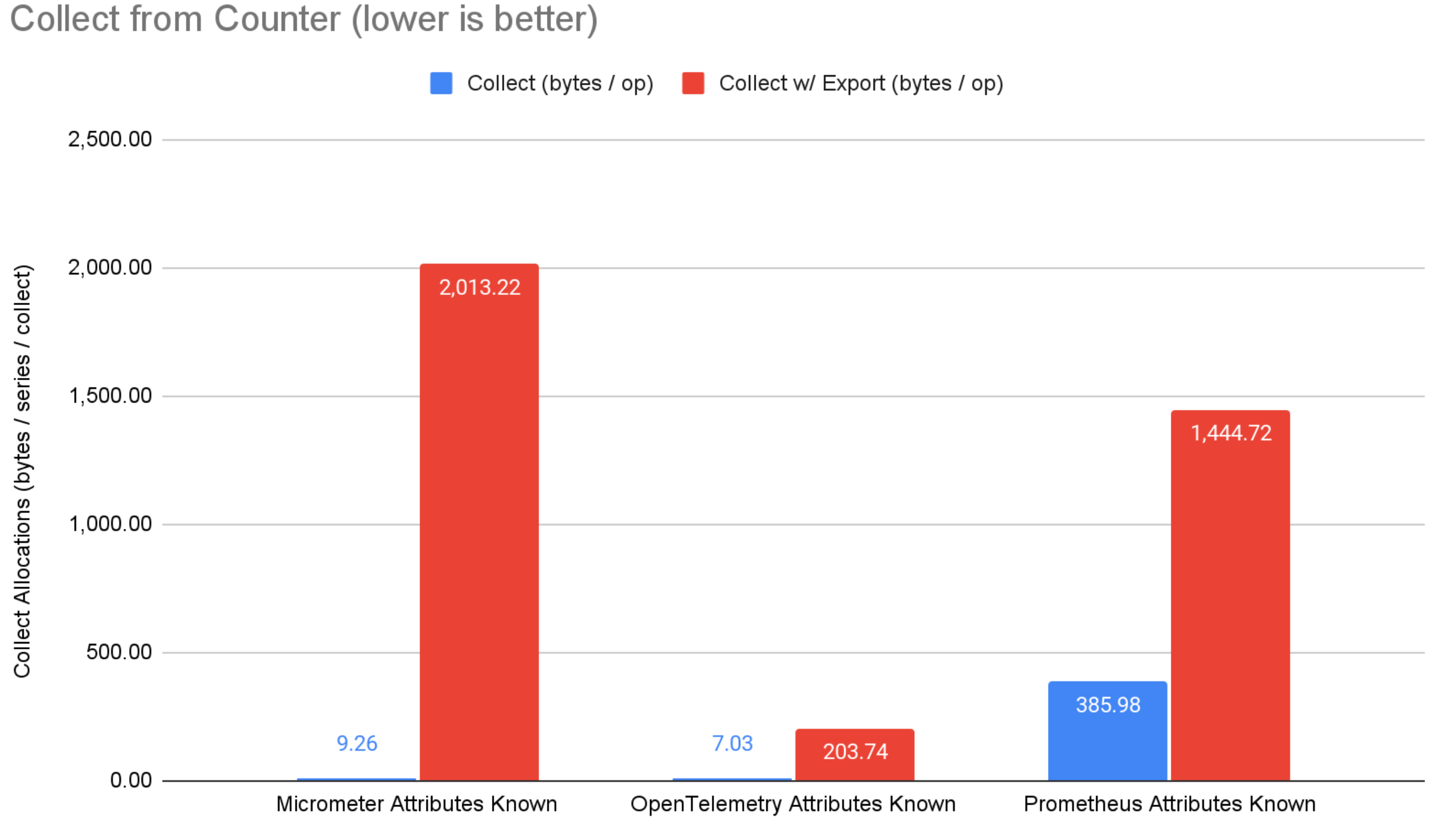
図4: カウンターからの収集ベンチマーク結果。
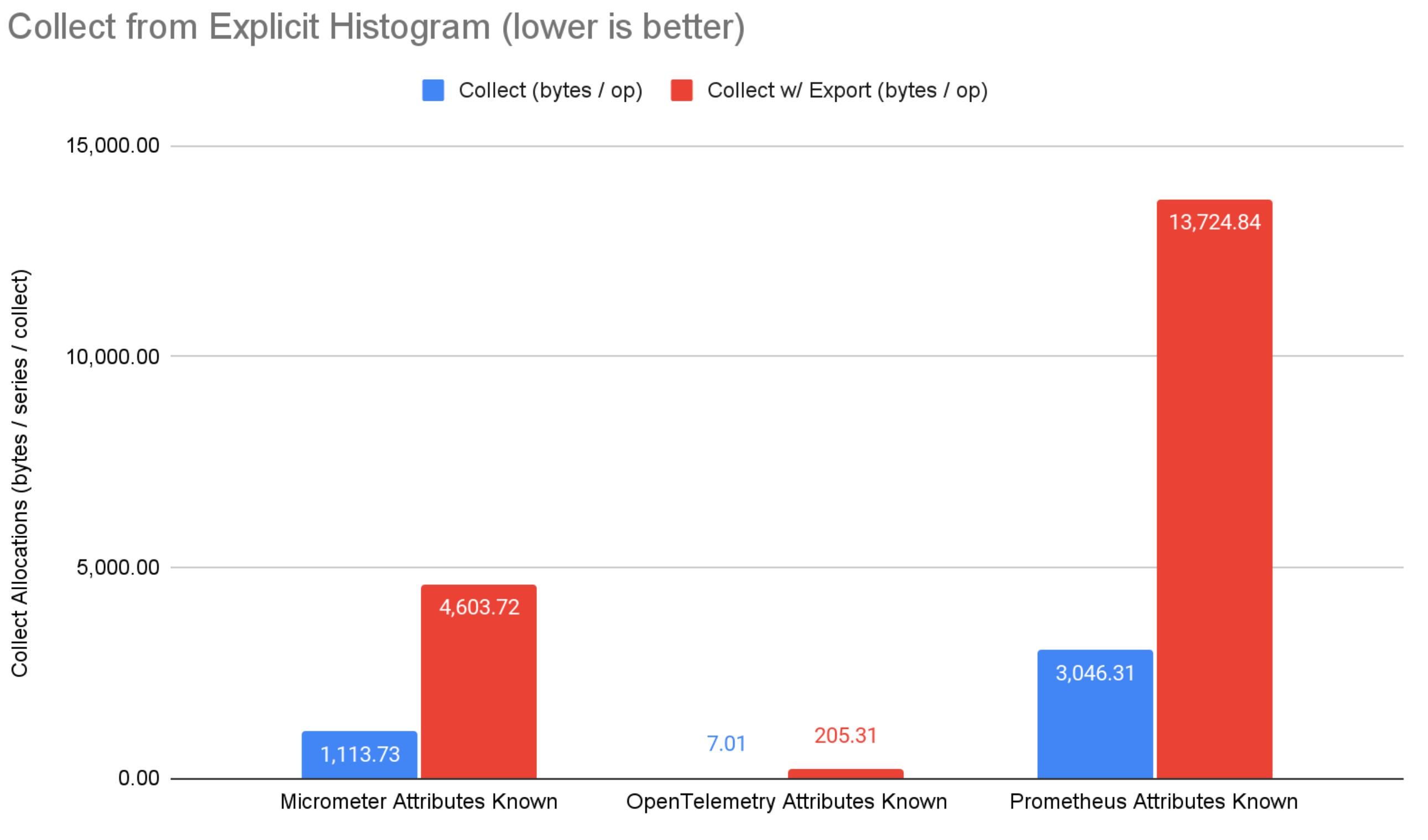
図5: 明示的バケットヒストグラムの収集結果。
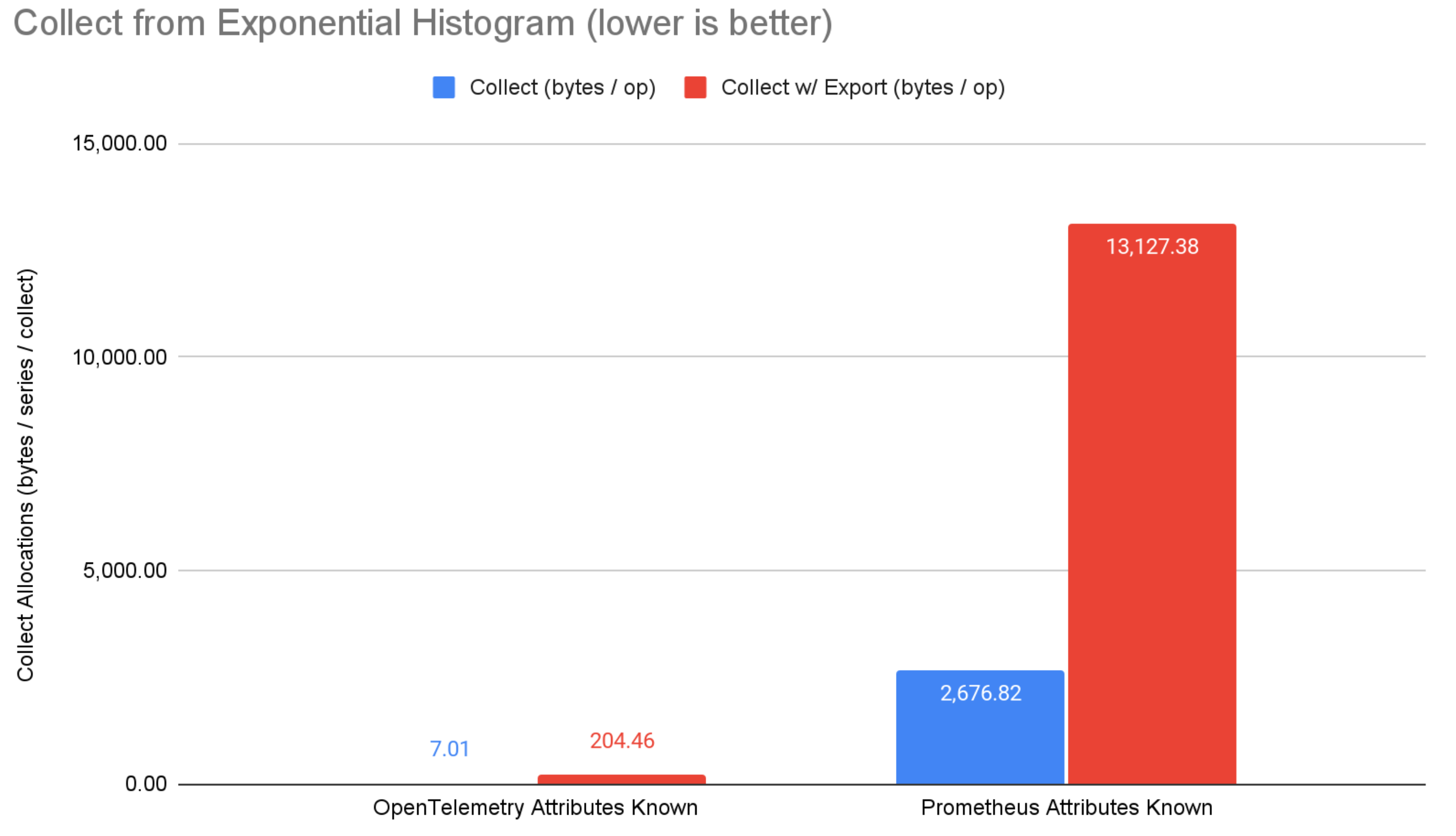
図6: 指数バケットヒストグラムからの収集ベンチマーク結果。
結論
記録側では、属性が事前にわかっている場合、micrometer と prometheus はカウンターにおいて 11ns の優位性があります。 バウンド計装を使用して集約状態への直接参照を取得し、マップ検索を回避しているためです(OpenTelemetry ではサポートされていません)。 それにもかかわらず、OpenTelemetry は明示的バケットヒストグラムにおいて 32ns の優位性があります。 これはおそらく、micrometer と prometheus が OpenTelemetry のヒストグラムの合計、最小値、最大値、バケットカウントよりも多くのサマリー値を計算しようとしているためです。 属性が事前にわかっていない場合、この優位性は縮小します。
属性値が事前にわかっている場合、どのシステムも記録時にメモリを割り当てません。 これは素晴らしいことで、あらゆる本格的なメトリクスシステムの基本要件であるべきです。 属性値が事前にわかっていない場合(つまり、アプリケーションコンテキストから計算される場合)、OpenTelemetry は prometheus や micrometer よりも一貫して少ないメモリを割り当てます。 OpenTelemetry はこのシナリオに明確に最適化されていますが、micrometer と prometheus は属性値が事前にわかっていることとバウンド計装に重点を置いています。 多くの場合、属性値は事前にわからないと主張しますが、これは micrometer や prometheus のいかなる優位性も限定的にします。 それでも、これは OpenTelemetry にとって改善の余地がある領域です。
収集側では、OpenTelemetry は非常に低いメモリ割り当てで際立っています。 エクスポートなしの収集では、OpenTelemetry は micrometer と prometheus よりも 22%〜99.7% 少ないメモリ割り当てです。 OTLP 経由の収集とエクスポートでは、OpenTelemetry は micrometer と prometheus よりも 85%〜98.4% 少ないメモリ割り当てです。 Prometheus は OpenTelemetry の OTLP エクスポーターライブラリを直接使用していますが、OpenTelemetryが垂直統合(つまりエクスポーターとコアメトリクスシステムが連携して最適な結果を達成する)によって実現できる最適化は利用しません。 micrometer の OTLP サポートは、メモリ内の micrometer 表現を生成された Java クラスに変換してからシリアライズするため、便利ですがパフォーマンスの観点からは最適ではありません。
全体として、これらは3つの本格的なメトリクスシステムです。 記録側ではすべてが見事に機能しており、すべてのシステムに費やされたパフォーマンスエンジニアリングの証です。 長い一連の最適化を終えた後、OpenTelemetry は収集側で際立っています。 低い割り当てはすべてのアプリケーションに恩恵をもたらしますが、特に高カーディナリティで厳格なパフォーマンス SLA を持つアプリケーションにとって重要です。
これを読んで Java メトリクスシステムを検討しているなら、OpenTelemetry Java を選んでいただけると嬉しいです。 単体でも強力かつ高パフォーマンスなツールですが、他の主要なオブザーバビリティシグナル用の API、豊富な計装エコシステム、さまざまな他の言語での実装、そしてよくサポートされたオープンガバナンス構造を備えています。
謝辞
ここまで到達するのを助けてくれたすべての opentelemetry-java コントリビューターに感謝します。 特に現在および以前のメンテナーと承認者に感謝します。 常にバーを高く設定し続けてくれた Asaf Mesika に特別な賛辞を送ります。